One of the interesting topics is estimation of RSocket limits in setup that approximates gateway serving tens of thousands clients.
There are numerous reports focusing on few streams over single connection, with emphasis on huge throughput. However this mode is not intrinsical for real server. Even though gateways are more likely to be cpu bound than IO bound, we can relax this assumption by making server logic trivial (just echo back incoming messages), to see how RSocket behaves under idealized conditions when major resource consumption is related to IO.
We use jauntsdn/rsocket to have http2 based transports,
and metrics that are actually useful (RSocket/RSocket-java metrics do not distinguish inbound/outbound messages,
generate redundant time series and seems were not designed with efficient querying in mind - at least for Prometheus case.
Also numerous vulnerabilities (1 ,
2,
3, 4,
5)
that were not resolved despite it’s post 1.0.0 GA hint that library is not
yet intended for internet facing services - use case we are interested in here).
Goals
- Multiple transports: tcp, websocket, http2, websocket-over-http2.
- Runs both locally and in data center (aws), ops/automation friendly.
- Distributed load clients.
- Keep-It-simple with test configuration options for load clients: number of connections per instance, number of streams per connection, ramp up interval.
- Test only long-running
request-streaminteractions - dominating model for clients connecting over the internet - browsers & mobile applications.
Software
Software stack is comprised of stable & widely adopted components:
Docker for building client/server images & running containers.
Test application images are created & saved to configured docker registry as part of project build process.
Nomad for containers scheduling with built-in docker driver.
Consul for service discovery. We register 2 services for load server instance
rsocket-stress-test-serverfor RSocket load itself.rsocket-stress-test-server-metricsfor http server exposing/metricsendpoint scraped by Prometheus.
Prometheus stores host, JVM & server metrics scraped from rsocket-stress-test-server-metrics endpoint.
Grafana does metrics visualizations used to evaluate performance.
Load server contains RSocket server parameterized with network/IO transports and security configurations.
Responder request-stream echoes back batches of original message at given intervals (effectively 1 message per second).
Load clients are configured with number of connections/streams, ramp up interval. They start new
streams monotonically until target count is reached. Request message contains random bytes, and is 1KB in size.
Both clients and servers use G1GC with default settings.
The application can be deployed locally, running load test with local infrastructure is a matter of changing few urls:
export DOCKER_REPOSITORY_ADDRESS=localhost:5000
export CONSUL_ADDRESS=localhost:8500
export NOMAD_ADDR=http://localhost:4646
Hardware
Server is equivalent of AWS c4.2xlarge - mainstream VM with 8 vCPU / 16Gb RAM / 1000MBit network.
Clients are c4.xlarge having 4 vCPU / 8Gb RAM / 1000MBit network each.
Comparable resources may be allocated on common developer’s box that helps with local experiments.
Test cases
Test application consists of 2 load clients connecting single load server instance.
Each load client is configured with env variables:
export CONNECTIONS=5000
export STREAMS=25
export RAMP_UP_PERIOD=250 #seconds
This results in 125k simultaneous streams per client, 250k streams per server over 10k connections.
Startup script generates Nomad’s job specification files from templates by substituting
configuration env variables, then asks Nomad to schedule test application.
First test is for TCP transport, configured for 250k, 500k, 750k and 1000k streams respectively.
We deliberately omit latency measurements until Part 2 - the goal is to determine maximum load before server starts to tip over.
Tcp, 250K simultaneous streams
250k streams over 10k connections, 125 seconds ramp up.
==> Client # of connections: 5000
==> Client # of streams: 25
==> Client ramp up period, seconds: 125
==> Starting server using scripts/server.nomad...
==> Monitoring evaluation "3b158360"
Evaluation triggered by job "rsocket-stress-test-server"
Allocation "2eae67ce" created: node "b4fd7677", group "servers"
Evaluation within deployment: "69514dd5"
Allocation "2eae67ce" status changed: "pending" -> "running" (Tasks are running)
Evaluation status changed: "pending" -> "complete"
==> Evaluation "3b158360" finished with status "complete"
==> Waiting 15s until server is started...
==> Starting clients using scripts/client.nomad...
==> Monitoring evaluation "00b0c5e7"
Evaluation triggered by job "rsocket-stress-test-client"
Allocation "38387f71" created: node "b4fd7677", group "clients"
Allocation "453a9469" created: node "b4fd7677", group "clients"
Evaluation within deployment: "4e7c3c74"
Allocation "38387f71" status changed: "pending" -> "running" (Tasks are running)
Allocation "453a9469" status changed: "pending" -> "running" (Tasks are running)
Evaluation status changed: "pending" -> "complete"
==> Evaluation "00b0c5e7" finished with status "complete"
==> Stress test started
==> It will be stopped automatically after 1h
==> Can be stopped manually with ./test_stop.sh
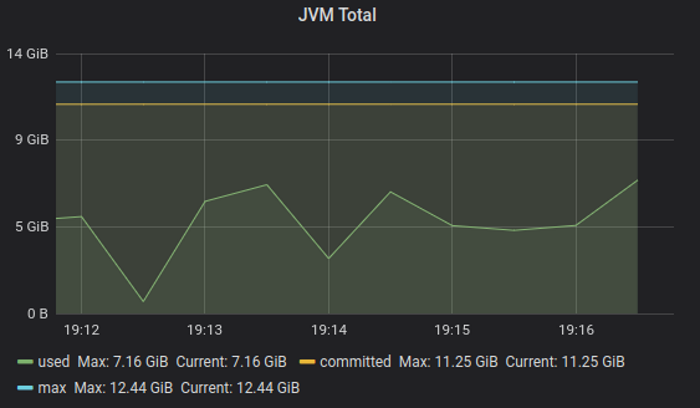
The base case has passed with moderate cpu usage: ~ 25%, total memory used peak (heap + non-heap) around 6GB.
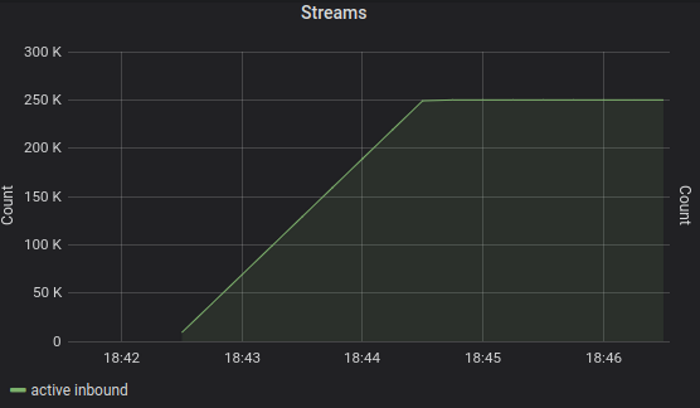
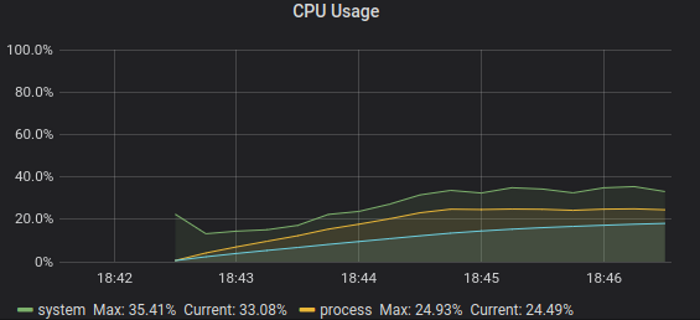
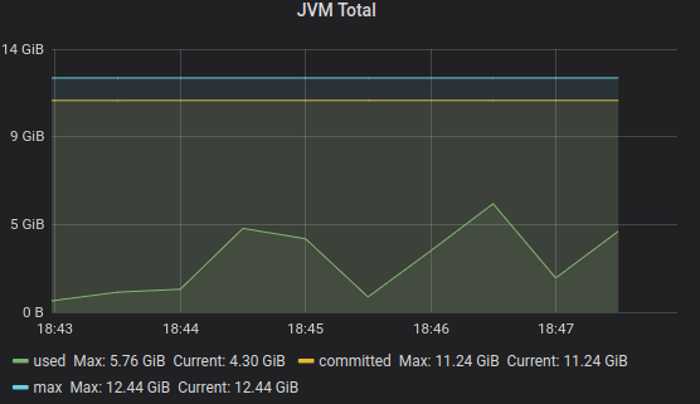
Tcp, 500K simultaneous streams
500k streams over 10k connections, 250 seconds ramp up.
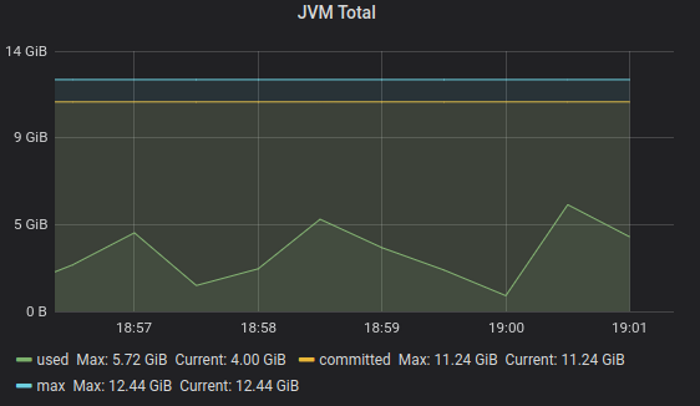
Cpu usage grows linearly with streams count: peaked at 50% for cpu, and same level of total memory peak: 6GB.
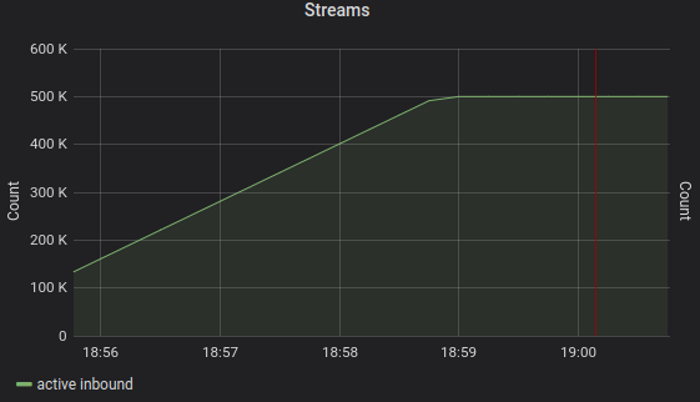
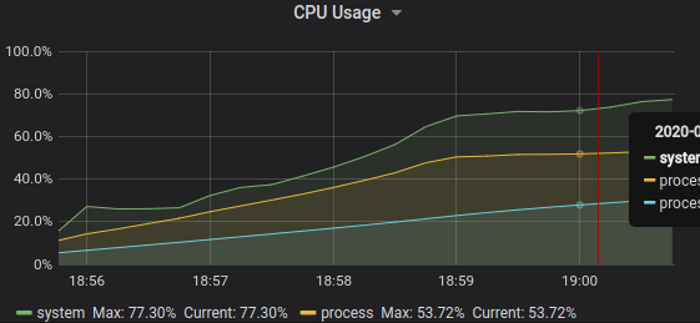
Tcp, 750K simultaneous streams
750k streams over 10k connections, 375 seconds ramp up.
Test demonstrates the server starts to tip over around 600k streams, 7 GB memory, 60% process cpu - but this time at 100% host cpu usage. The result is an artifact of scheduling both server and clients on same host, and actual streams peak is higher - around 700-750k will consume 70-75% cpu - practical limit for stable service operation.
The number is promising as there are few opportunities for optimizations - as will be shown in part 2 of the post.
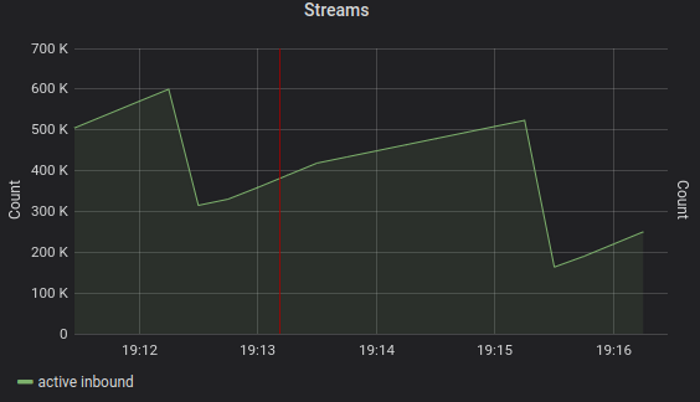
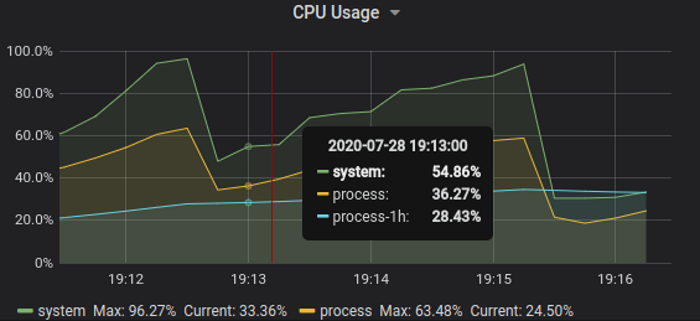
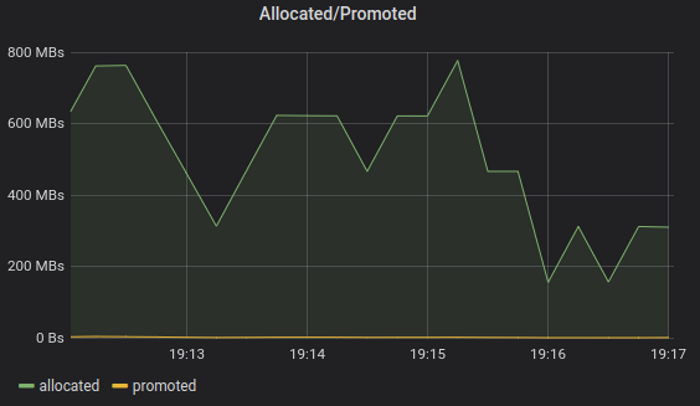
Interesting observation - allocation rate peaks at 800MB/s even though load server application code does not allocate
directly. Handful of objects instantiated by library per message are significant contribution to total GC pressure once
number of messages becomes millions.
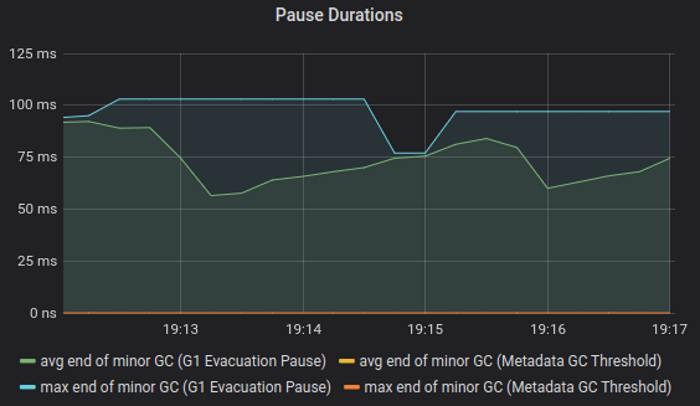
GC pauses of this run, for reference
Part 2
In second part we will continue with design decisions review of the original library, their impact on performance and how It can be improved.