New year break is good time for continuing on topic of one million of streams - serving huge amount of RSocket streams simultaneously with single, mid-level commodity computer.
The original library gave in around 500k streams - mark where server was still stable, at whopping 500-600 MBytes/s allocation rate - unexpected numbers for RSockets just sending same byte buffer periodically, using library advertising zero-copy capability.
Interesting question is whether we hit natural limit, caused by current state of JVM runtime and libraries, or is a consequence of design choices driven at large by “ideological” and marketing motives that eventually resulted in implementation having significant parts happen to exist just for burning CPU cycles - both directly and through garbage collection?
Let’s start with the numbers: performance comparison of original rsocket/rsocket-java library
versus jauntsdn/rsocket-java redesigned with pragmatics-first approach.
Numbers
Tests were performed on the same hardware described in first part of report, using TCP for transport. Host box is 16 vCPU / 32 gb RAM; 8vCPU/16gb is allocated for server, and 4vCPU/8gb - for each of 2 clients.
500k
500k streams over 5k connections; graphs show server active streams and CPU usage, respectively
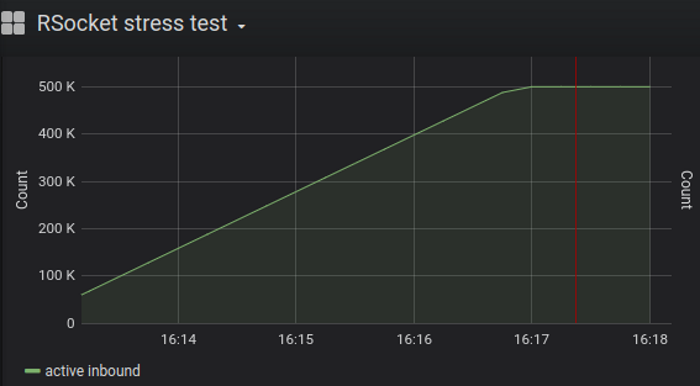
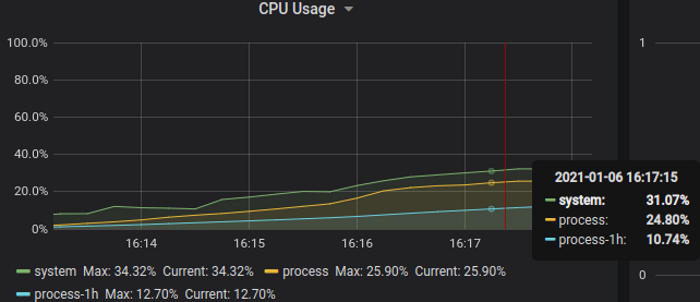
Server based on redesigned library consumes 25% CPU vs 50% CPU original (part 1: TCP, 500K simultaneous streams), yields 2x improvement.
1000k
1000k streams over 10k connections; graphs show server active streams and CPU usage, respectively
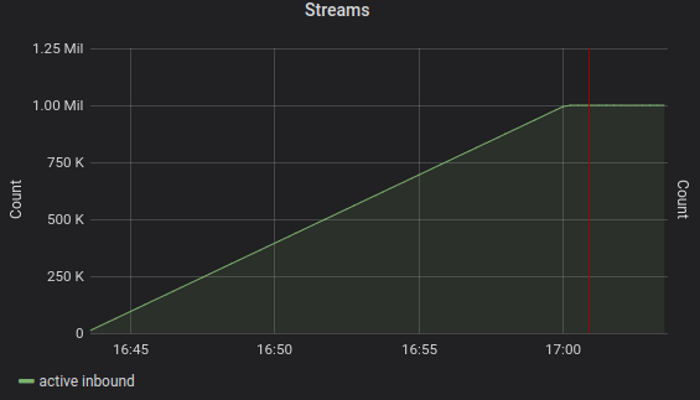
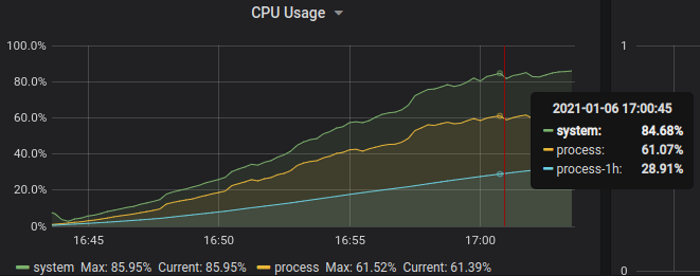
Test server is stable while handling 1 million of simultaneous streams at 60% CPU usage (and 80% host CPU, which also includes 2 clients) - value is comparable to 50% CPU with original library at only 500k streams.
Graphs demonstrate that 1 million streams goal is met with new implementation while consistently using 2 times less CPU.
Let’s take a look at server heap allocation rates.
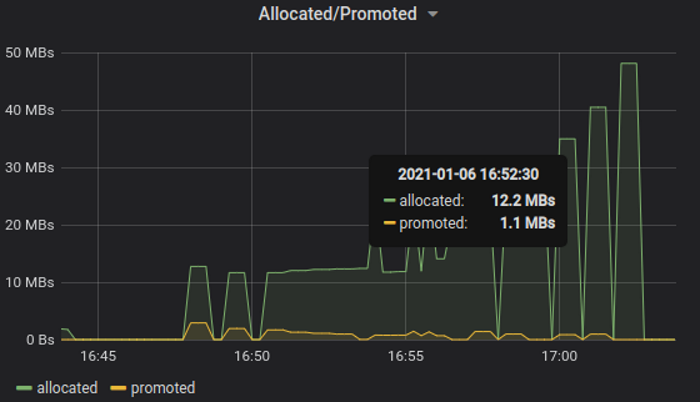
Allocation rate peaked at only 50 MBytes/s - quite an improvement over 800 MBytes/s (just on ~600k-700k streams) of original library.
Given that streams interval is 1 sec, this corresponds to 50 MBytes allocated on heap per 1 million messages, or at most 50 bytes per message sent.
The cost of reactive
Rxjava/project-reactor style libraries are useful because they enable lock-free asynchronous message processing
with user-friendly, fluent “functional”-style interface, are composable and offer good throughput-latency tradeoff.
This makes them a good choice for user-facing APIs on network applications. However, It does not necessarily hold true for internal components underneath API surface - fluent style and composability are not free.
Some operators, e.g. flatMap
contain non-trivial logic and do 2 CAS updates per message, others (groupBy)
additionally exchange each message via SPSC-queue. On loaded servers with tens of thousands streams
It is common to see 10% of total CPU time spent inside flatMap itself!
Reactive everywhere
Original library rsocket/rsocket-java followed reactive dogma little too rigorously, and DuplexConnection -
its main transport interface, internal component for sending and receiving frames - exposes APIs as Publishers chained
with said flatMap and groupBy for processing inbound and outbound messages.
This dependency also forces every transport to implement reactor-netty adapters for a single purpose of sending/receiving raw bytes,
even though reactor-netty primary use case is HTTP.
Let’s get into details.
Reactive type in send method DuplexConnection.send(frames)
is redundant - It accepts Publisher<ByteBuf> of frames instead of simple synchronous method:
void send(ByteBuf frame);
Reactive type in receive method DuplexConnection.receive()
is redundant - It returns Flux<ByteBuf> instead of method with callback:
void receive(OnReceive onReceive);
interface OnReceive {
void receive(ByteBuf frame);
}
RSocket itself is lightweight protocol and does not require asynchronous processing of messages, hence Publisher instead
of synchronous function is unnecessary complication.
One can argue Publisher on DuplexConnection.send()/receive() are for flow control, but there is upper bound
for pending messages already, provided by protocol itself: outstanding streams are limited with request leases,
and outstanding stream messages - by reactive-streams semantics of RSocket.
Odd assumptions
RSocket is intended as foundation for messaging systems, and they are designed as single-producer systems.
Multi-producer designs are expensive because at scale of million+ messages managing contention takes unacceptable
amount of CPU time compared to message processing itself.
RSocket-java relies on Netty as backbone for its frame transport implementations.
Netty is go-to messaging/networking toolkit on JVM, and It follows event loop pattern - inbound messages
of one connection are delivered on same thread - single producer. On outbound pipeline most of Netty components
also aware of event loop so writes have low overhead.
However there is no concept of event loop in original rsocket/RSocket-java - outbound frames are exchanged via
MPMC queue plus 2 CAS writes,
even if every outbound frame is on event loop thread.
This is not hypothetical situation - proxy/loadbalancer applications naturally have both inbound and outbound messages produced on same thread.
Accidental inefficiency
Inbound and outbound streams state is stored in a map with all methods declared synchronized.
It is 2 ways problematic - first inbound frames apriori can’t race because they are published on event loop hence no locking needed - still noncontended locks are not free. Then this adds contention between outbound request frames and inbound frames for no particular reason. Code that appears like highly optimized for throughput lives next to locks on a hot path.
Because DuplexConnection.receive() returns Flux<ByteBuf> of incoming frames, part of processing logic is
implemented as chain of operators inside ClientServerInputMultiplexer.
Unfortunately It does so with aforementioned flatMap, groupBy and another Processor having
good old 2 CAS operations and MPMC queue exchange.
This chain of operators is replaceable by plain function call.
Frame properties are read from memory multiple times for each message: streamId, frameType, flags, data & metadata - instead of reading once and pass down callstack.
Also there is needless allocation for each outbound frame with payload caused by CompositeByteBuf.
Complexity
reactor-netty is main networking library in Spring/reactive ecosystem. Spring framework core ideas are flexibility
and productivity - virtually any component is pluggable, many components are available out of the box.
reactor-netty follows same line in spirit as new features and configuration options are added to project on first user request.
This leaves an impression of unbounded scope - reactor-netty is not just thin reactor-core adapter
around Netty’s channels.
Internal structure wise, It has layers of functions-calling-functions of Monos/Fluxes, and other clever constructs manifesting in screen-sized call-stacks - net contributing only to wasted CPU cycles and allocation rates.
Usability wise, there is unfortunate decision to combine reference-counted offheap memory with async streams of
reactor-project in user-facing APIs. Decision became burden on its users - who now are required detailed knowledge
of reactive-streams rules, project-reactor and reactor-netty primitives lifecycle to not leak native memory
while doing common client/server tasks.
Redesign
The goal of rework was addressing problems outlined above, let’s enumerate main points:
-
Adopt straightforward design across library where every component exists for good reason; external dependencies are lean and justified.
-
Replace reactive types with simple function calls / callbacks on all transports.
-
Drop
reactor-nettyfrom transport, use Netty directly since It gives fine-grained control over connection bytestreams, removes the need to workaround reactive “ballast” that gives no value in transport context, plus leaner dependencies that are more stable, easier to understand and maintain. -
Simplify hot paths of sending and receiving frames: header attributes are calculated once, drop necessity for
CompositeByteBuffers, dropClientServerInputMultiplexer- manifestation of operators abuse is also replaced by a single plain function. -
RSocket inbound streams - bridges from plain callbacks to reactive interactions(request-stream, request-channel etc) - were reimplemented assuming event loop execution model with single producer.
-
Drop locks on a hot path of accessing streams maps - this is consequence of Netty event loop awareness in both streams and transport.
Conclusion
Keep-it-simple approach, well articulated scope, lean dependencies are necessary components for software infrastructure library.
If principles are not respected, library ends up comprised from more-than-necessary components each having hardly noticeable deficiencies, once stacked together contribute considerable amount to CPU waste.
In this particular case waste was 50% - and is directly reflected in hardware costs of each application on top of It.